Let Your Data Talk: An Illustrated Guide to RAG with LangChain – Benefits and Relevance in 2024
TL;DR
RAG enhances LLM reasoning by giving it access to your data, improving response accuracy and relevance. By keeping the model away from the data, it ensures data privacy, allows incremental updates, and offers an efficient, cost-effective solution for developing GenAI applications.
Langchain is a framework that streamlines development by providing reusable components, allowing you to adapt your app architecture to the volatile landscape of evolving GenAI tooling.
In this article, we will delve into the inner workings of RAG pipelines, compare it with the long context window approach and highlight the distinct advantages of custom RAG implementations over managed solutions.
Contents
Intro
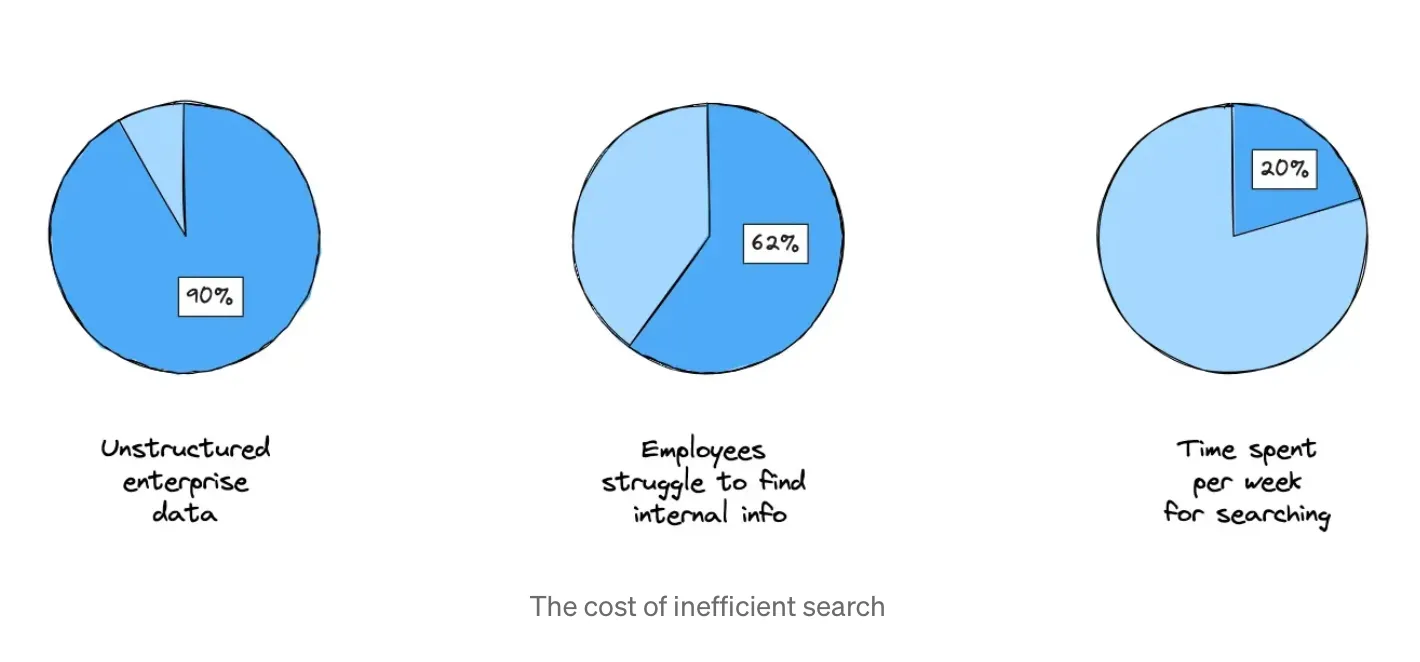
According to ResearchWorld, up to 90% of all enterprise data is unstructured. Microsoft’s Work Trend Index states that 62% of employees struggle searching for internal information. McKinsey estimates that locating this unstructured data consumes 20% of the average working week. Taking the average salary statistics for an IT specialist in Germany from Glassdoor, it is easy to calculate that the time spent on inefficient search costs the organisation €11k per employee per year.
With the advent of ChatGPT, access to the entire body of human knowledge now takes only a few seconds. Unfortunately, this only applies to publicly available LLMs trained on public data.
What if we could combine the ability of public LLMs to answer user questions in natural language with the use of internal data without compromising it?
What Is RAG?
Retrieval augmented generation (RAG) is an architectural pattern for GenAI application, a technique that aims to solve the above-mentioned problem of LLMs by augmenting their knowledge with custom data. It combines data retrieval and text generation to improve accuracy by bringing the context to the LLM.
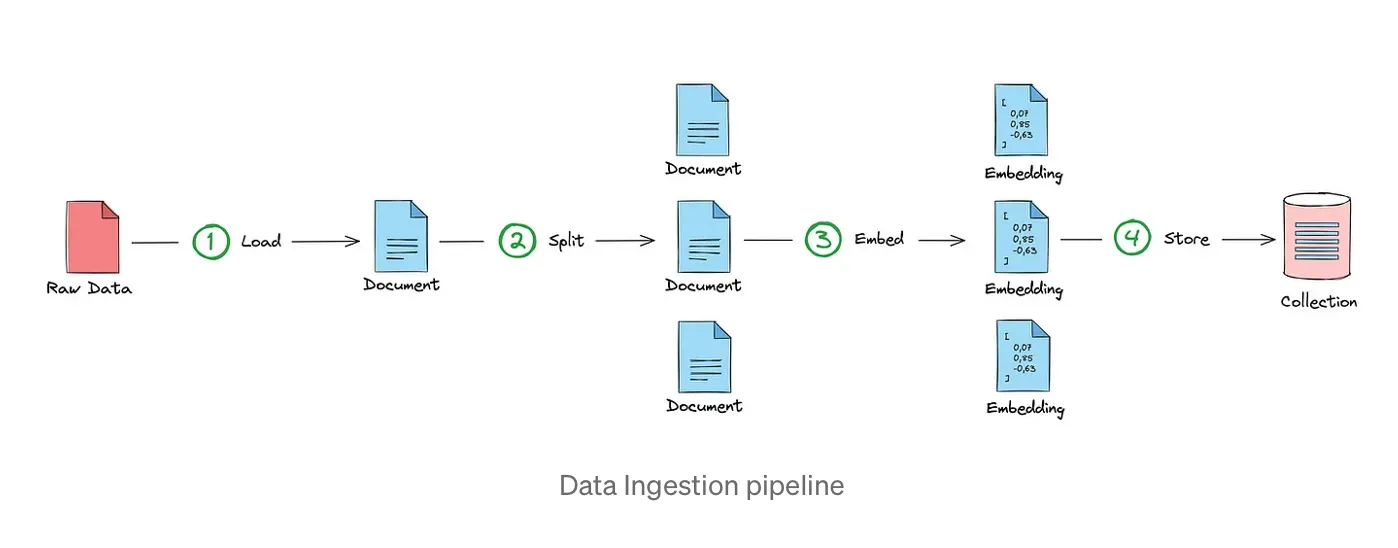
A typical RAG application consists of two pipelines: Data Ingestion and Retrieval & Generation. In the Data Ingestion pipeline, data is loaded, processed, and stored in a format suitable for efficient retrieval.
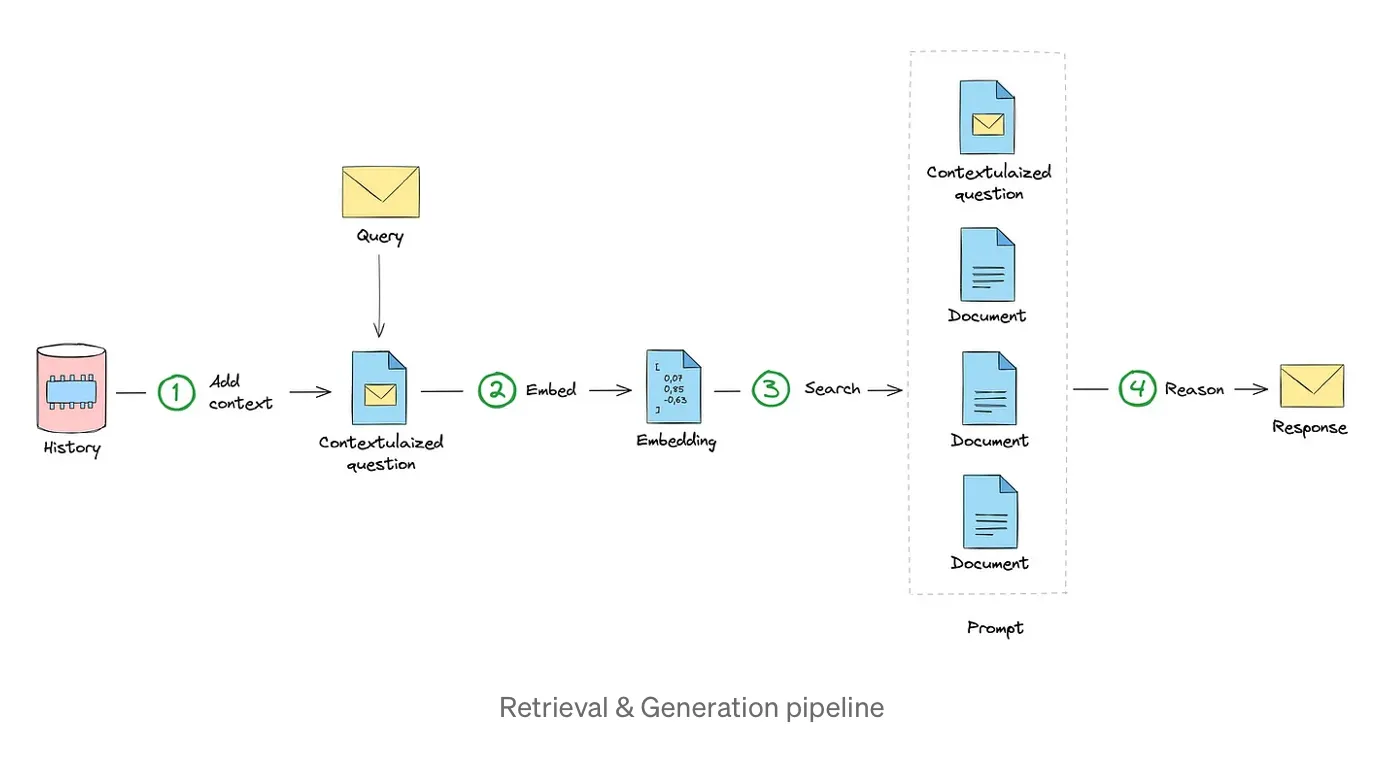
The Retrieval & Generation pipeline involves querying the ingested data and generating responses based on the retrieved information using LLM.
RAG solves the problems of LLMs, such as accuracy and reliability, by linking them to external knowledge bases while keeping the models and knowledge bases apart.
Why Langchain?
In the era of rapid AI tooling development, committing to a specific tech stack for your AI-based application and thereby fixing the architecture to particular providers means setting yourself up for failure right from the beginning. The ability to easily replace them, both at the system design stage and in the running application, becomes a crucial requirement for the architecture.
Unfortunately, there is no common standard that AI application components adhere to, making their replacement impossible without affecting other components of a system. Let’s say you are fascinated by the massive context window of Claude and are eager to replace your current GPT-4 Turbo with it. You would need to deal with Claude-specific API, payload type, authentication, prompt handling and whatnot.
Langchain is a framework that provides a standardised API that abstracts the differences between various LLMs, vector stores, and other components. It allows developers to switch between different technologies & providers without changing the application code significantly.
Langchain comes in two flavors — Python and Typescript. Introduced initially in Python for primarily research-focused, machine learning enthusiasts, Langchain was recreated in Typescript natively. Moreover, the artifacts (prompts, chains, agents) can be shared between the two languages.
Data Ingestion
Data ingestion involves transforming documents into a uniform format, splitting them into context-preserving chunks, embedding the chunks as numerical vectors, and storing these vectors in a database optimized for similarity searches.
1. Load
This step aims to transform one or more user-provided documents into a uniform Document format containing plain text and metadata. While converting a Word document to a plain text format may seem quite straightforward, the problem becomes non-trivial when it involves parsing formats like PDF, snapshots from a database, or even extracting text from images.
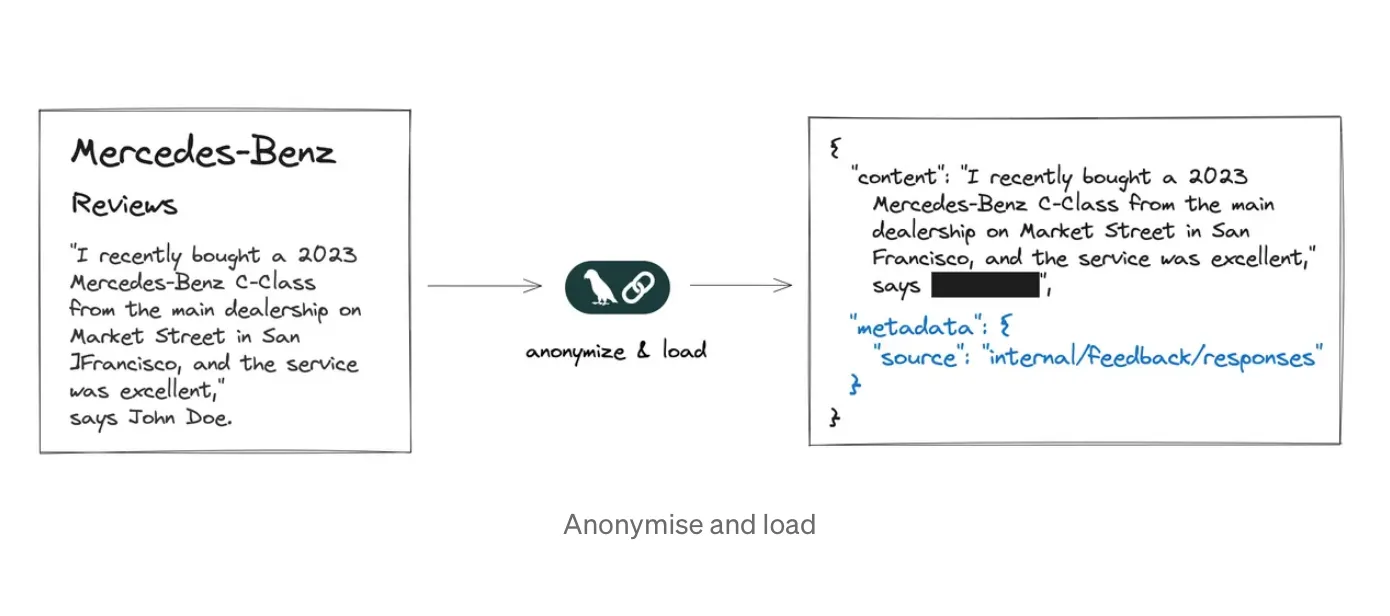
This is also the step where personally identifiable information (PII) can be removed or redacted.
See the source.
2. Split
At this stage, large documents are split into smaller documents or chunks. Later, when the user asks a question, the most relevant chunks are retrieved and used to answer the question.
As simple as it sounds on the surface, the devil is in the details. The primary challenge in this process is maintaining the semantic relationships between chunks, ensuring that meaningful connections between them are not lost. Improper text splitting could result in the separation of closely related information.
One possible strategy for structured documents, such as markdown files, is to split while maintaining a reference to parent headers.
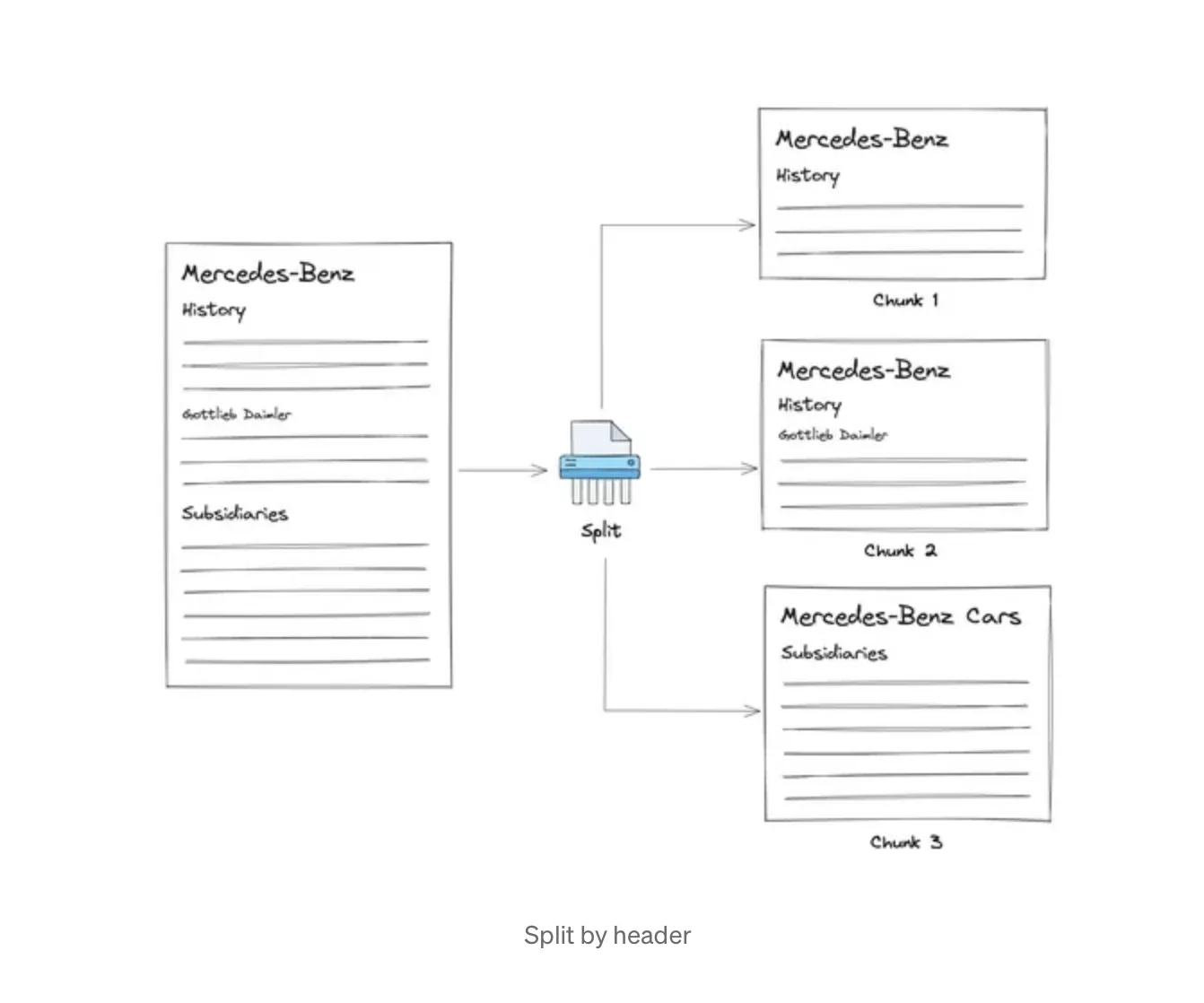
The chunks should be small enough to contain one unit of information. At the same time, they should maintain a connection to the context surrounding the chunk and contain as little noise as possible. A good chunk is the one that makes sense to humans without further surrounding context.
There’s no one-size-fits-all solution to chunking, and it heavily depends on the content of your documents, particularly how they are structured. The experiment done by LlamaIndex reports that a chunk size of 1024 is optimal for balancing performance and response quality.
See the source.
3. Embed
Vector embeddings are words and sentences converted into numbers representing their meaning and relationships. Embedding is a sequence of numbers between -1 and 1 representing semantic meaning for a given piece of text in the multi-dimensional space. There are special types of models that are trained specifically to generate vector embeddings, and MTEB (Massive Text Embedding Benchmark) regularly updates the list of the most performing embedding models.
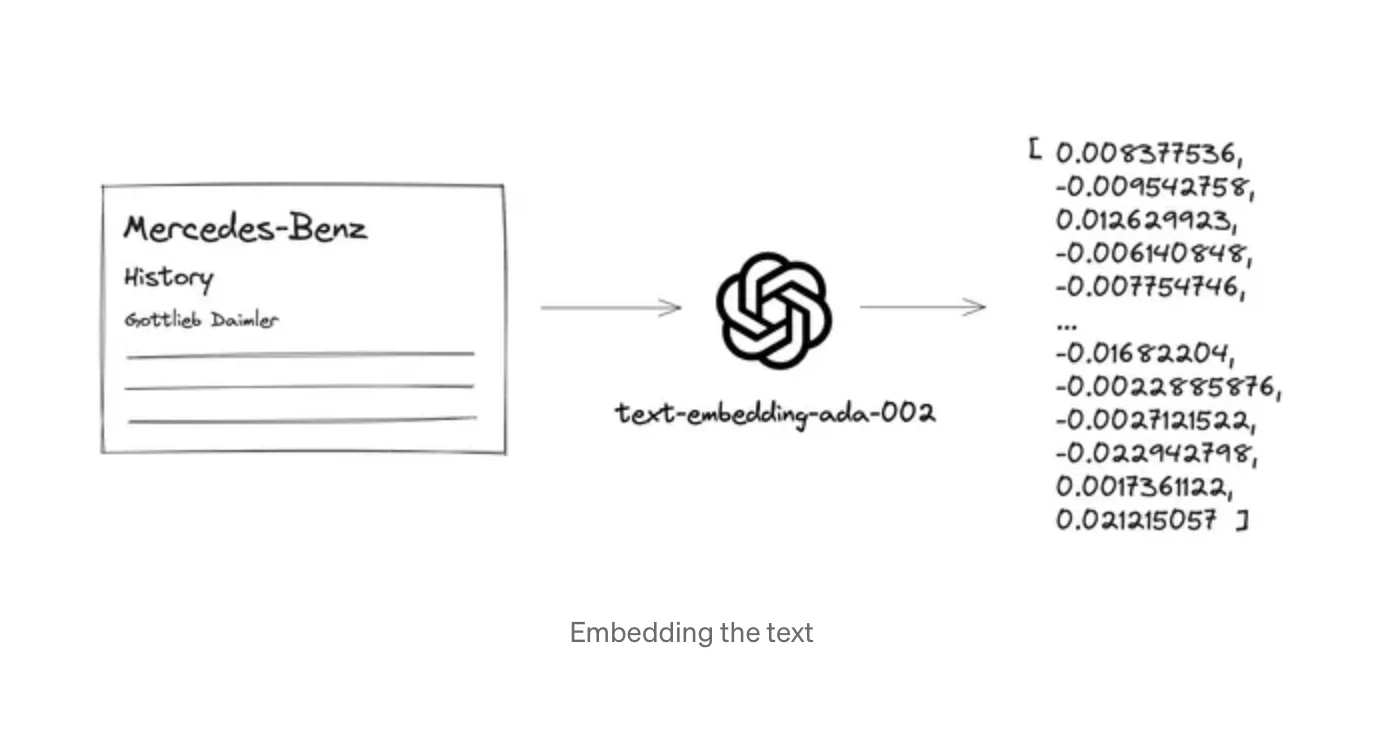
Applying different embedding models to the same exact text will generate different embeddings. Models differ in dimension size, which is fixed per model. No matter how long your given text is, it will be embedded into a vector of a size defined by the model. Think of it as a hash function with added semantic value.
Embeddings enable operations like semantic search and thematic clustering. This is fundamental for RAG, where we look for chunks of split text most relevant to the user’s question. While searching for the “best” matching chunks, we look for the closest embeddings in the multidimensional space. Thus, vectors for the words “Fish” and “Dog” will be closer than those for “Fish” and “Table”.
4. Store
After being generated, vector embeddings are inserted into the vector database, which is designed to store them and is optimised for handling high-dimensional data operations, such as vector search. In traditional databases, we search by querying the rows to find exact or partial matches to our query. Instead, in vector databases, we use similarity metric to find embeddings that are most similar to our query.
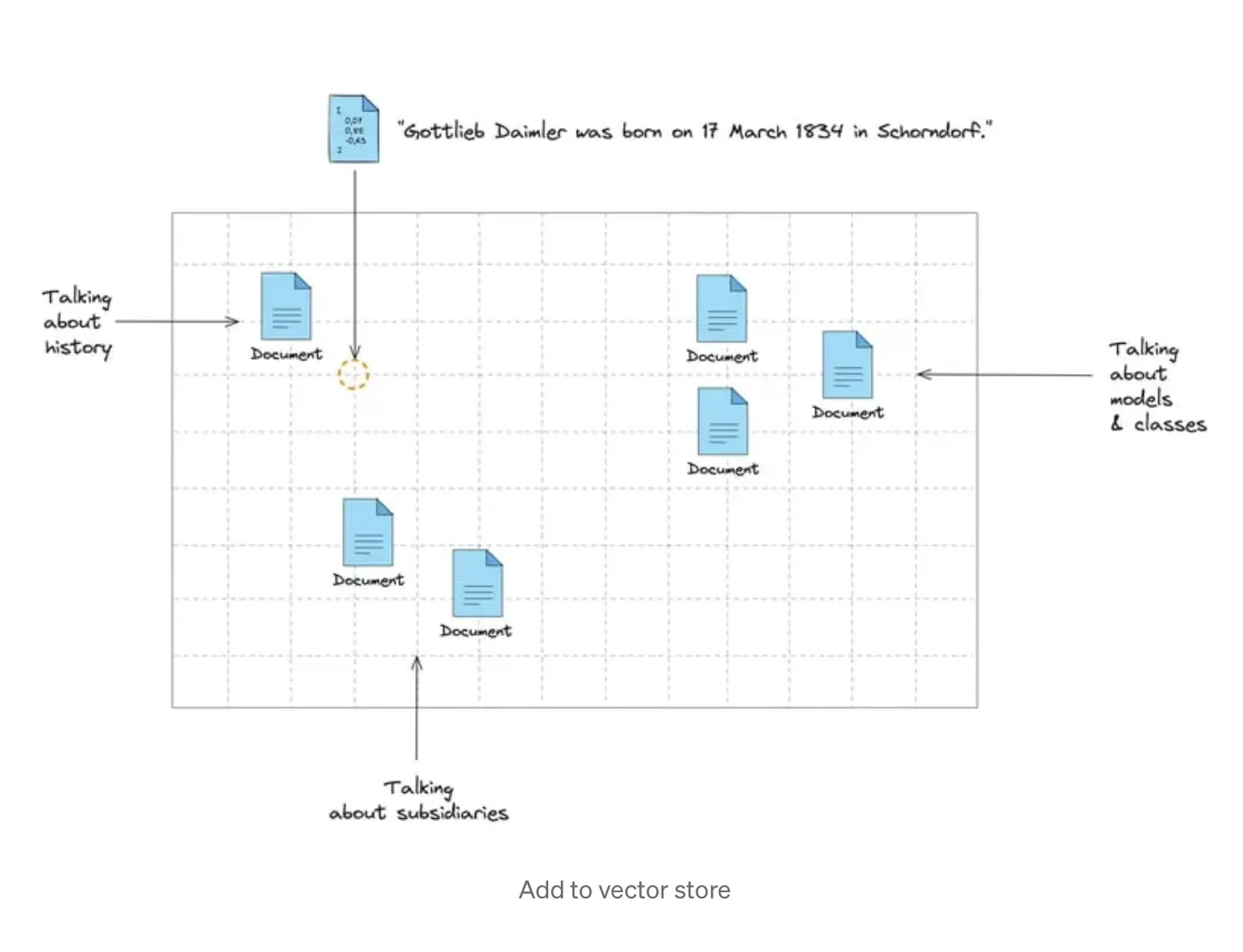
Langchain, an open-source framework for developing AI applications, supports more than 90 vector stores and provides a generic interface for populating the store, adding, removing, and searching by vector. This makes it easy to switch from one provider to another when needed.
See the source.
Explore More
This article was originally posted on Medium. Click here to read the full version.
Related articles

André Félix
From Cool Demos to Production Reality: Insights from the April Lisbon JUG Java Meetup
At Mercedes-Benz.io, we actively engage with local and international tech communities to explore how emerging technologies can be applied responsibly in enterprise environments. In April, we were proud to take part in th
May 19, 2026

Romina Muenchow-Centili
AI in Service Management: Driving Efficiency, Quality and Impact
Artificial Intelligence (AI) is no longer a distant promise in Service Management, it is already reshaping how teams work, think and deliver value. In this edition of Technkowledgy, Romina Muenchow-Centili, Service Manag
May 12, 2026

João Almeida
Behind the Engine: How Carl.AI Scales Knowledge Access at Mercedes-Benz.io
At Mercedes-Benz.io, not every product we build is visible to customers. Some of the most important ones work quietly behind the scenes, shaping how teams collaborate, share knowledge, and build digital products more eff
Apr 28, 2026