
Dive into DevSecOps
DevSecOps is the combination of development, security, and operations practices to reduce the time needed to deliver changes in the system—ensuring high quality with integrated security practices.
Goals:
- Improve deployment frequency;
- Faster time to market;
- Lower failure rate of new releases;
- Shorter time to fix something;
- Faster time to recovery (if a new release crashes the current system).
At Mercedes-Benz.io we want to have this in our DNA but we can not only continuously improve on what we do but also need to evolve as everything around this concept also evolves. Mindset, tools, and strategies to improve the teams structure are changing and we need to keep up, take advantages of new findings in the technology community, and, whenever possible, also lead the way.
Organizational challenges for effective DevSecOps
When we think of DevSecOps, we imagine the idyllic scenario with developers using a stable and secure platform for fast delivery of new product features. But what is actually involved in achieving this ideal? How close are we to reaching this goal?
From my experience over the years, I have seen some awesome work being developed in this field and experienced what is happening in our and other companies. Thus, I came to the conclusion that DevSecOps success involves 3 main factors: the right mindset, technology and an appropriate organizational structure.
These factors form a base triangle where several other aspects on DevSecOps should be applied and/or followed, so that we can continuously improve our products and the way that we deliver them to their users.
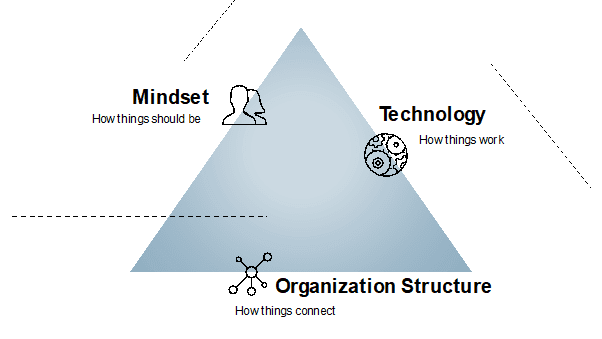
The vision of having a triangle made with Technology, Mindset and Organization Structure on the DevSecOps picture
With this triangle in mind, we should guarantee the context where we build our products and chase the "delivery flow" – the place where we are in peace with the delivery process and happy with what we deliver.
When technology is what we use to build technology
This point mainly reflects the need of technology to provide solutions for faster and recurring delivery. Many say that DevOps is not about the tools but while I agree it is also true that we need tools—provided by someone else or made by us— to help us on the delivery flow and optimize the delivery process.
In terms of process, I would add that we should seek to use the tools that can help us optimize the process as early as possible in the team’s delivery process.
We can cluster the technology in two major clusters:
- Tools that we use or build to improve the delivery flow
- Flexible platform Infrastructure
Tools to improve delivery flow
The delivery process has several steps, and we can introduce tools to improve the product and the way that it is built.
Here some examples of technology usage to improve the product and its delivery:
- Tools that help on the Coding/Development phase, for example, Source Code Management Tools for managing the code and the team(s) collaboration model, or tools for Code Quality evaluation over best practices as early as possible.
- Tests for different product functionalities and business rules should be applied with the help of tools that help on its automation.
- We also have tools available to help on the Code Review and Pair Programming, to improve the team collaboration and the result of that work.
- Automated pipelines for Continuous Integration and Continuous Delivery/Deployment with automatic evaluation of possible vulnerabilities in terms of Security and Compliance.
- Logging, Monitoring and Alerting are supported by several tools that can connect all information allowing peaceful sleeping and faster troubleshooting.
- For Performance we can use tools to improve the overall experience of our users and also to evaluate what can be decreasing performance and be improved.
The above list has some of the areas and tools where automation is the key for delivery improvement. Every challenge we have can be an opportunity for improvement and to add more items to this list.
There’s a lot of tools out there that we can use and to choose the best one for what you need is also a challenge by itself. It’s important to understand why you need it, if it’s better to use a tool already available or if you need to build one that fits best to what we need.
Additionally, to the value the tool can give, we should also evaluate the effort for integration and maintenance, keeping in mind that we should control the amount of cognitive load that we add to our product teams.
Flexible infrastructure
Also related with the technology for DevSecOps, we have the infrastructure solutions to provide a flexible and—we hope—stable base for our products. This infrastructure can be made available as a Service (IaaS), extended to a Containers as a Service (CaaS or KaaS if the container solution is based on Kubernetes) or a Platform as a Service (PaaS) like the one we have with PCF. Each one adds a layer on the previous providing easier to use features but, most of the times, removing some flexibility in the usage of that infrastructure.
Over this infrastructure base, we can (and should) provide software services—for example, based on tools—and present them as a SaaS (Software as a Service) to be used by the product teams, if possible, in a self-service manner.
The evaluation and choice of possible tools should be done with everyone involved in the product development, from Architecture to product and platform teams. This is one of the things we are actively doing in several Proof of Value/Proof of Concept initiatives at Mercedes-Benz.io.
A tool is good if we know how to use it****… and if it fulfills a purpose
When we started to talk about DevOps, around a decade ago, I remember this image of development connected with operations with no barriers. An infinite loop with people working together but also a handout phase pictured with 2 colours: one for Development and the other for Operations.
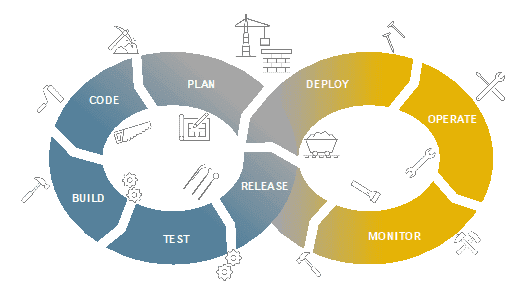
Dev and Ops connected in an infinite loop
Around this infinite loop we can have all the tools to help on each stage and the idea there was to connect Devs and Ops in the most streamlined possible manner.
For me, that picture is outdated, and the following image is what I can picture nowadays.
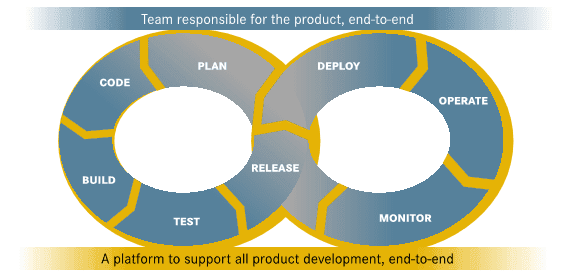
DevOps infinite loop
On the above picture we have a team the owns the product end2end, in all phases, supported by a platform, enabling the team to focus on the business and on how to improve the product.
I see this as an updated mindset over DevOps and a key factor for companies to improve the way their products are delivered to their users. No handovers, no predefined/discussed responsibilities, everyone working together to ensure the best products. A platform made by platform teams focused on providing the best platform services, developing a platform as a product. Products with product teams focused on delivering value to their users.
This mindset is totally aligned with the “you build it, you run it” principle and we can partly extrapolate the “eat your own dog food” practice, as each team should guarantee what is delivered to the product users and get direct feedback when something needs improvement.
From this DevOps picture to DevSecOps, we “just” need to add the Security we need to have around what we deliver, with the intrinsic mindset and some tools to help on that.
We need a structure to enable the mindset and good usage of technology
In terms of structure, I have been following the important work that Matthew Skelton and Manuel Pais are doing, around team topologies, in the past few years. In my point of view, they are setting the standards for DevOps team structures, bringing some definitions, a common language and some practices that, when correctly applied, can help organizations improve the way their products are built and delivered.
Next, I’ll point out what I think should be addressed when you want a good structure for your DevOps teams.
Design the organization following the architecture you want for your product

If we know that the produced software mimics the team’s communication structure, why don't we just use the wanted architecture to structure our teams?
The idea here is to apply the so-called Reverse Conway Maneuver, starting by the definition of the wanted software architecture for the product(s) and then, defining the teams to produce the software according to that architecture.
Easier said than done, I know. Not starting from scratch means that a usually non-pacific transformation is needed. But expecting that your product will follow an Architecture guideline that your team structure doesn’t follow—we already know that will not happen.
Manage the complexity of each team’s domains to decrease cognitive load!
We should also look at the complexity that each team needs to handle and control.
As we empirically know, our capacities are always limited and we should maximise the individual capacity to process new information, resolve problems, and learn.
In a simplistic way, we can look at our working memory when we need to do a task. The working memory is loaded with 3 types of information:
- the intrinsic load with all the information we know and need to resolve the task,
- the extraneous load with all the information that exists in the context and is unnecessary or unproductive to do the task but is there – like some existent processes and bureaucracy - and,
- the germane load that we use to understand and find a solution to solve the task.
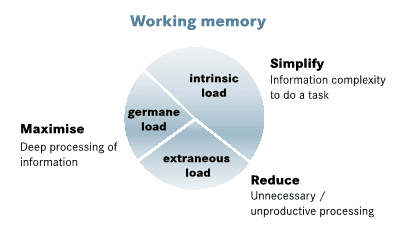

If our context is too complex, our available working memory is already filled with information leaving no space for solving the task in an ideal way. If the team has a lot of processes and bureaucracy to deal with, that information is fulfilling the available working memory, and again, removing space for solving the task in the best way.
That is why we should simplify the complexity around one team and reduce the unproductive information each member has to deal with, in order to leave space for the germane load, to better solve each issue and deliver innovative solutions.
Size matters!
Here I’m talking about the ideal group size to maximize teamwork and results.
Dunbar’s number show us the limits of the number of people we can have, socially, together and have closer connections. We should extrapolate that to the groups in our company structure—underlining the type of relations we have at each organizational groups.
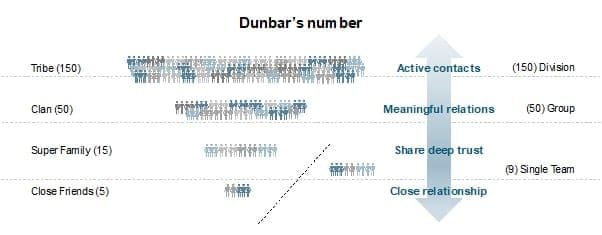
Groups size and the kinds of relations
So, yes, size matters and we should use this knowledge to set the best team size on our structure.
Identify the topology of your teams and their modes of interaction
Team Topologies give us the fundamental topologies that we can use to identify our teams and the interaction modes to define how they interact with each other’s.
Here are the team topologies we should use to define our teams:
- Stream-aligned teams are the full-stack, cross-functional, product teams.
- Enabling teams are the ones that help the stream-aligned teams to adopt or modify software, as part of a transition or learning period.
- Complicated subsystem teams, previously defined as component teams, should be used only when needed and by a period of time, to manage a complex subsystem that the stream-aligned teams can’t handle by themselves.
- Platform teams are the ones supporting stream-aligned teams on their product delivery.
If used well, these are the only topologies we should need to define the type of teams we have on our DevOps structure.
Besides the topology of each team, we should also define the interaction modes each team have with the other teams. Here are the core interaction modes we should use:
- Collaboration for teams working together for a period of time to discover new things like APIs, practices, technologies, etc.
- X-as-a-Service when one team provides, and one team consumes something “as a Service”.
- Facilitation when one team helps and mentors another team.
These definitions should help us identify the teams we have and the teams we need, improving, at the same time, the communication by having a clear and simple definition to connect the organization.
A practical aspect of these definitions passes by creating small artifacts like the “Thinnest Viable Platform” for platform teams or “Team API” for all teams, to share this throughout the organization, improving the visibility and understanding of its structure. Follow the links to see the relevant information that we should have on those artifacts.
Use a platform to reduce the cognitive load from product teams
We should define and use a platform to build the common pieces that enable the product delivery, removing some of the complexity, and the inherent cognitive load from the stream aligned teams.
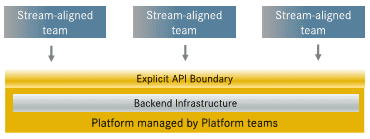
Common platform used by stream-aligned teams
This is the so-called platform model and, as stated on the “2020 State of DevOps Report”, when “(…) done right, it simply works, resulting in faster, more efficient delivery of high-quality software that meets an organisation’s business needs — and at scale. One platform to help product teams”.
This platform model relies on having a platform built as an internal product that has the stream-aligned teams as customers. On the platform we need cross-functional teams to build it and follow the organizational structure concerns mentioned above.
As we are aiming for the best way to help the delivery process, the platform should, as much as possible, provide self-service solutions to the stream-aligned teams to optimize integration. We can aim for a NoOps concept, providing the delivery environment fully automated and abstracted from the underlying infrastructure.
What do we need to improve our delivery?
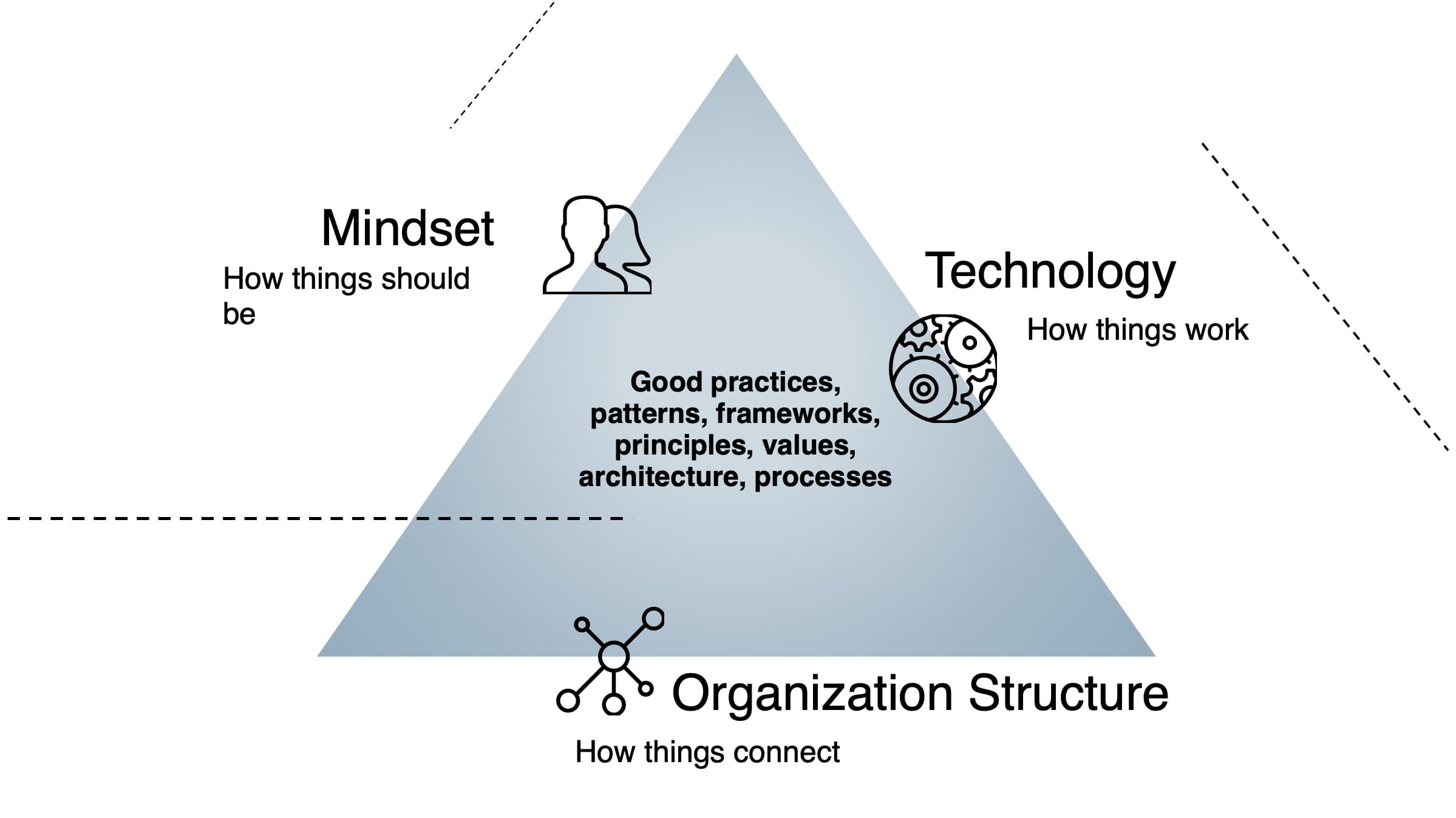
The triangle as a base for all best practices
Wrapping it up, we have the triangle formed by Technology, Mindset and Organization Structure, as the base to apply good practices, patterns, frameworks, principles, values, architecture, processes… Everything that we can do to improve our products and the way we deliver them, but requires a good base to be able to work as best as possible.
As the old sailor saying goes: “there’s no good wind for those who don’t know where they’re going”. Nobody can do it alone and it’s nothing one can command, it’s something for which we are all accountable for. We should use this triangle to guide and direct our efforts, create a common language, and aim for the same place.
Related articles

Catarina Marques, Mariana Pereira
What OFFF Barcelona Taught Us About Design, Emotion, and Creative Risk
Every year, OFFF Barcelona gathers some of the boldest, brightest, and most unapologetically creative minds in the design world. It’s a space where visual artists, designers, and storytellers connect; not just through stunning work, but through the philosophies and emotions behind it.
May 30, 2025

Bernardo Oliveira
How can modern tooling save Mercedes-Benz.io engineering time?
In today's fast-evolving JavaScript ecosystem, modern tooling plays a pivotal role, influencing not just how we code but how much time and money we spend doing it.
May 16, 2025

Porfírio Ribeiro, Thiago Martins
What Vue.js Amsterdam Taught Us About Tech, Community, and Growth
Every year, Vue.js Amsterdam gathers developers from around the world for two days of talks, learning, connection, and lots of fresh energy. It’s a chance to zoom out from day-to-day tasks and dive into what’s shaping one of the most loved JavaScript frameworks — and this year, a few of our MB.ioneers were there to experience it firsthand.
May 9, 2025