
From Bottleneck to Backbone: How We Accidentally Built a Company-Wide GenAI Platform (And Lived to Tell the Tale)
When knowledge becomes hard to access, support bottlenecks follow. At Mercedes-Benz.io, what started as a small idea to reduce internal support turned into a company-wide GenAI platform, one that empowers teams to build their own assistants, securely and autonomously. In this article, Site Reliability Engineer João Almeida shares how we scaled structured AI to make knowledge easier to find, workflows faster, and autonomy the default.
Contents
From Prototype to Platform
Here’s the thing about platform teams: we love helping people. We really do. But when you’re answering “how do I configure this AWS thing?” for the 47th time that month, you start questioning your life choices.
Our team at Mercedes-Benz.io was hitting that wall hard. Every new team meant more tools, more knowledge scattered across Confluence pages that nobody updated since 2019, and more questions that we’d definitely answered before… somewhere… in some thread… if only we could find it.
We needed a breather. More importantly, we needed to stop being the human equivalent of a search engine for internal docs.
So we did what any reasonable engineers would do: we built a bot. A simple LLM-powered assistant that lived in GitHub Discussions, trained on our docs and previous support threads. Nothing fancy, just “please answer this question so I don’t have to.”
And it worked. Like, surprisingly well. Within days it was deflecting tickets faster than they could pile up.
But here’s where it got interesting: every single team that saw our little prototype had the same reaction: “Can we have one too?”
That’s when it hit us. This wasn’t our problem. This was everyone’s problem. Every team was drowning in their own knowledge swamp, fighting the same battle against buried documentation and repeated questions.
Which meant… oh no… we couldn’t just build a bot. We had to build a platform.
Turning “It Works on My Machine” into “It Works for 50 Teams”
Right, so if we’re doing this properly, we need to solve the actually hard problem: how do you let multiple teams use the same infrastructure without their data leaking into each other’s assistants? Because explaining a data leak to the security team is not on my bucket list.
The answer: full tenant isolation from day zero. Each team gets their own sandbox, separate storage, separate processing, separate permissions.
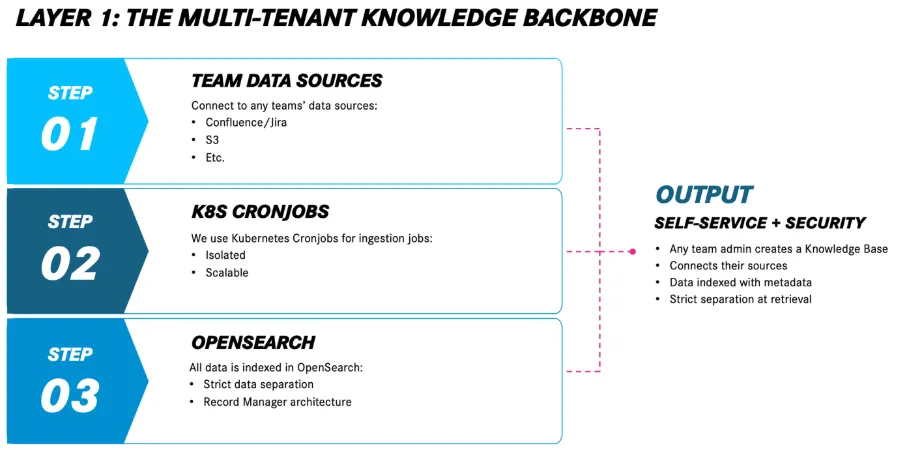
Each tenant connects to their own data sources: their Confluence spaces, their GitHub repos, their Jira projects. No mixing, no accidental leakage, no awkward conversations with InfoSec.
Now, the limitations (because of course there are limitations): we capped each knowledge base at 10 data sources. Could we do more? Sure. Should we? Probably not, unless you enjoy response times measured in geological epochs. More sources = better recall, yes, but also more noise and slower retrieval.
Self-Service at Scale
Here’s the thing about good platform architecture: it’s only as useful as the interface that exposes it. We could’ve built the most elegant RAG pipeline in the world, but if teams had to file tickets to get an assistant, we’d just be recreating the bottleneck we were trying to eliminate. That’s what we call “failing with extra steps.”
So, we built a self-service UI. Non-technical users could spin up a fully configured assistant in under five minutes. Pick your data sources, apply some filters, choose an LLM model, optionally tweak the system prompt if you’re feeling adventurous. Done.

This completely flipped our role as a platform team. Instead of being the bottleneck (ironic, I know), we became enablers. Knowledge ownership shifted from “file a ticket and wait for João to answer” to “the team who writes the docs also owns the assistant that serves them.”
Extending Capability with a Developer-First API
The UI was great for quick setups, but developers being developers, they immediately wanted more.
The answer is yes, because we exposed the whole RAG pipeline via an OpenAI-compatible API. Swap out “api.openai.com” for our internal endpoint, and boom: you’re accessing your scoped knowledge base with the same SDKs and tools you already know.
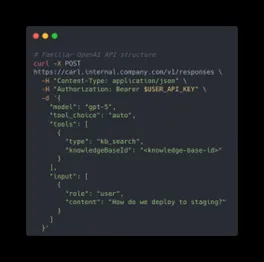
This was powerful for two reasons:
- Zero learning curve: If you’ve used OpenAI’s API, you already know how to use ours
- Security by default: API keys are bound to tenant-scoped data access, so you literally can’t accidentally query another team’s knowledge base, even if you try
This API became the glue layer. Teams built integrations with CI/CD pipelines, support dashboards, release note generators, even test case recommenders, all pulling from their own knowledge graph.
The IDE Integration, or: Death to Context Switching
Despite all the cool platform features, the real unlock came when we brought assistants directly into the IDE.
By leveraging the Model Context Protocol (MCP), we created dedicated MCP knowledge base servers, allowing developers to interact with their team’s context and documentation directly from their workspace.
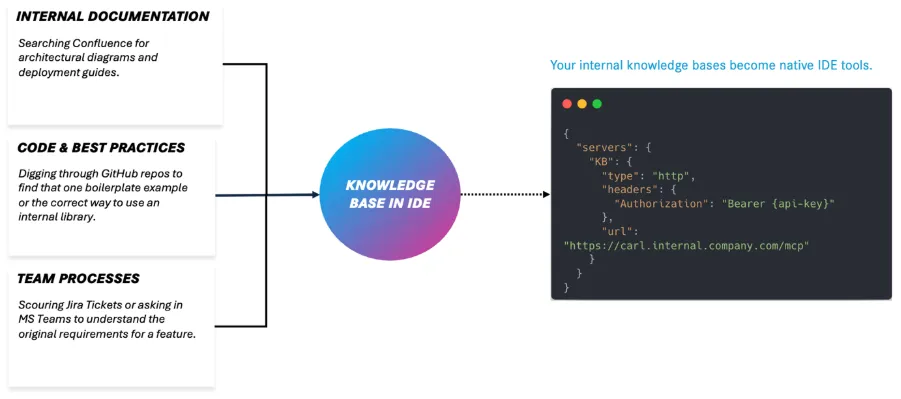
Need to check deployment policies? Ask in the IDE. Confused about a GitHub Actions workflow? Ask in the IDE. Want to know how another team solved a similar problem? You guessed it: ask in the IDE.
This removed one of engineering’s most persistent annoyances: tab sprawl. No more juggling five browser tabs, searching through Teams history, or interrupting your teammates. Just ask once, get a structured answer grounded in your team’s actual data, and get back to shipping code.
Rethinking Support Entirely
The platform eliminated first-line questions, empowered teams to manage their own knowledge access, and surfaced information that was previously buried in the documentation graveyard.
It also created an unexpected feedback loop: if your assistant gave confusing answers, it usually meant your docs needed work. Suddenly, teams started caring about documentation quality. The system enforced good practices naturally, which is the best kind of enforcement.
Every team got the tools to define, govern, and scale their own knowledge access. The value wasn’t just in removing our burden (though that was nice). It was in giving everyone else the autonomy to move faster without waiting for us to unblock them.
Scaling Forward: What’s Next for Our GenAI Platform
We’re far from done. The roadmap includes support for bring-your-own MCP integrations, more granular connector controls, and the introduction of A2A (agent-to-agent) orchestration, allowing assistants to chain tasks or collaborate asynchronously.
We’re also experimenting with fine-tuning layers that let teams define tone, priority, or escalation logic, giving more personality and precision to their agents without retraining models.
A few lessons have stayed with us:
- Treat internal AI like infrastructure, not a feature.
- Compatibility matters more than novelty.
- Context lives in the workflow, meet people there.
- Self-service isn’t about removing humans; it’s about removing wait times.
We’re just getting started. But this time, it’s not about scaling support, it’s about scaling autonomy.
P.S. If you’re wondering whether this approach works at your company: probably? The patterns are pretty transferable. Just remember that the hard part isn’t the tech, it’s convincing people that self-service won’t break everything. Spoiler: it won’t. Probably. Mostly.
Related articles

Pedro Henriques, Ricardo Mano, +1
KotlinConf 2026: When Type Safety Meets Intelligent Systems
What happens when a language built on clarity and reliability meets a setting driven by AI and speed?
Jun 23, 2026

Karla Silva
Selenium Conference 2026: AI, BiDi, and the Future of Test Automation
From May 6 to 8, the Selenium and Appium Conference took place in Valencia, bringing together the global automation community for three days of technical discussions and knowledge sharing. Built by the community and for
Jun 12, 2026

Alexandra Teixeira
The Art of the Juggle: Balancing Business, Team and Ownership as a Product Owner
Being a Product Owner (PO) often feels like standing at the centre of multiple worlds at once. There's the business, moving fast and reacting to market pressure; and also, the team, deeply invested in the product, armed
Jun 9, 2026