
Node Scaling Optimization at Scale: Cut your Kubernetes cluster costs while assuring zero downtime
At Mercedes‑Benz.io, the platform organisation operates a large number of Kubernetes clusters that power dozens of digital products across the company. As a central platform team, we own the underlying infrastructure and its operational reliability, while product teams own their applications and deployment lifecycles.
Running Kubernetes at this scale is both exciting and challenging, especially when each product team has unique, often unpredictable compute and scheduling needs. In this article, I’ll walk through one challenge we faced with cluster autoscaling, workload fragmentation, how static instance sizing led to cost waste, and how we solved it by partnering with Cast.ai to bring dynamic, workload‑aware autoscaling to life.
Contents
Where It All Began: Static Node Autoscaling
Most Kubernetes teams rely on the Kubernetes Cluster Autoscaler as the standard mechanism for automatically adding or removing worker nodes based on workload demand.
At first, we did the same: each cluster scaled inside a default AWS Autoscaling Group using m5.xlarge instances. In theory, this should have been fine but in practice, two major issues quickly emerged:
-
Static Instance Sizes Don’t Fit Dynamic Teams
Every product team has different resource requirements; some need large machines for data‑heavy workloads; others need many small ones.
With a one‑size‑fits‑all setup:
- If a workload required more resources than what one m5.xlarge could offer, the team had to file a service request → manual intervention, delays, overhead.
- If a workload needed less resources, the node was underutilized → wasted compute, wasted money.
-
Maintaining Instance Families Became a Full-Time Job
AWS introduces new instance families constantly, so maintaining, testing, upgrading, and validating these within the platform became tedious, extremely time‑consuming and not valuable work for our stakeholders.
We wanted autoscaling that adapts to workloads automatically, not the other way around.
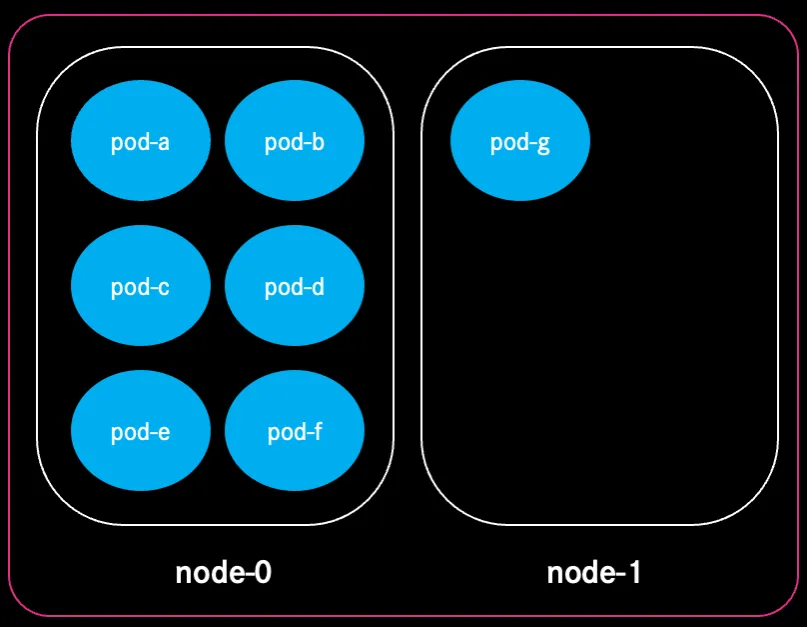
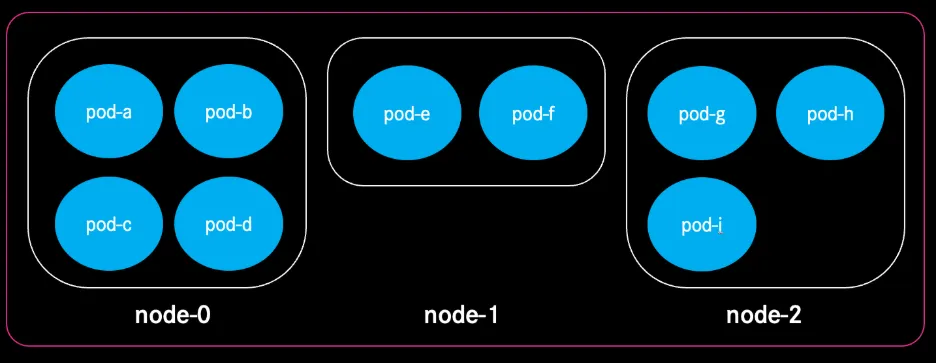
The Hidden Cost: Cluster Fragmentation
Autoscaling node sizes and default Kubernetes scheduling configurations introduced another problem: fragmentation.
Once a pod is scheduled onto a node, it stays there until the node is drained. Over time, this leads to:
- uneven distribution of workloads.
- nodes with leftover “holes” of unusable CPU/memory.
- clusters requiring more nodes than necessary.
This is where bin‑packing strategies come in, techniques to compact workloads more efficiently, so nodes run at healthier utilisation. But implementing custom scheduler rules or Kubernetes Descheduler configurations across more than 120 clusters isn’t trivial and adds more operational overhead.
We needed something more automated and easier to maintain.
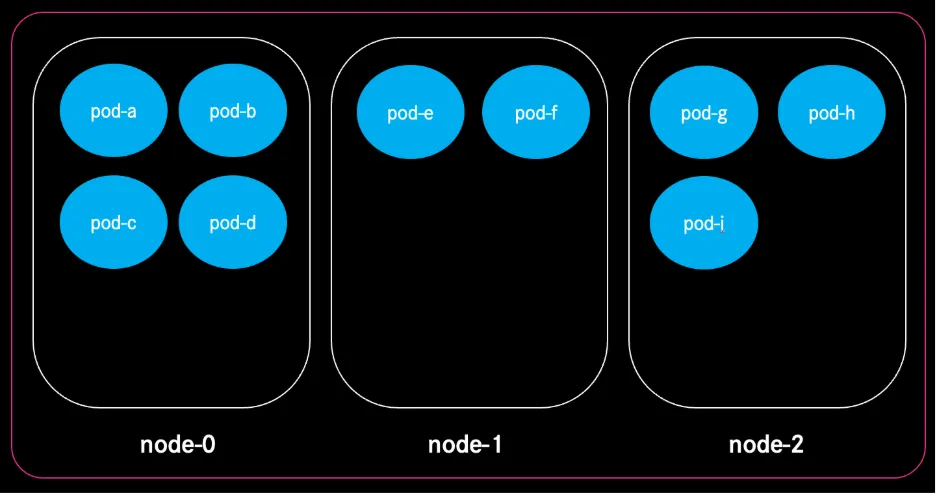
Dynamic Autoscaling with Cast.ai
To solve these challenges, we partnered with Cast.ai, whose agent-based autoscaler replaces the default Cluster Autoscaler.
The main difference is that, instead of scaling with fixed instance types, the Cast.ai autoscaler:
- selects the best instance family and size dynamically based on actual workload requests,
- works in a Karpenter‑like fashion, launching nodes that perfectly fit pods,
- significantly reduces operational overhead by handling instance type diversity automatically.
This ensures that nodes match workload needs exactly, teams get the resources they need instantly, and costs drop because we no longer over‑provision.
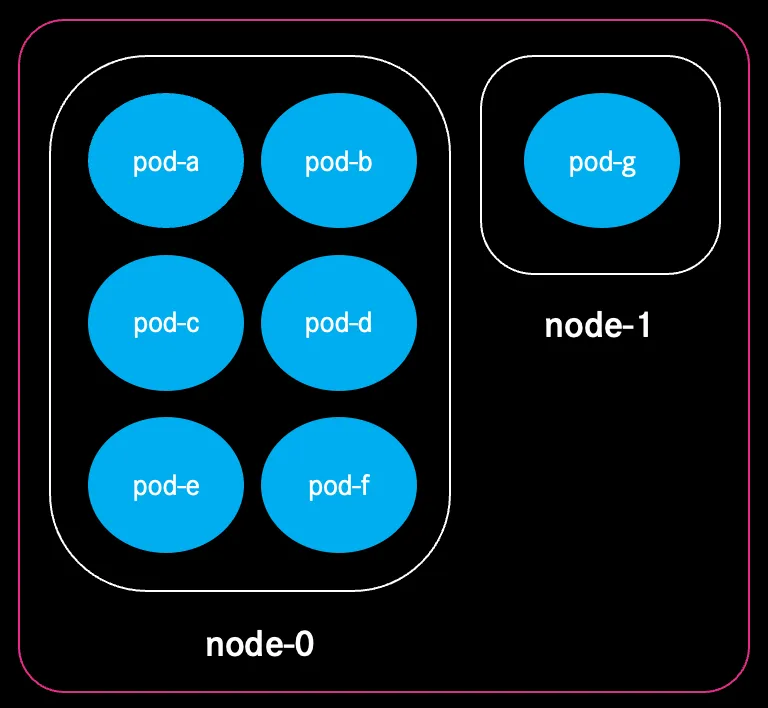
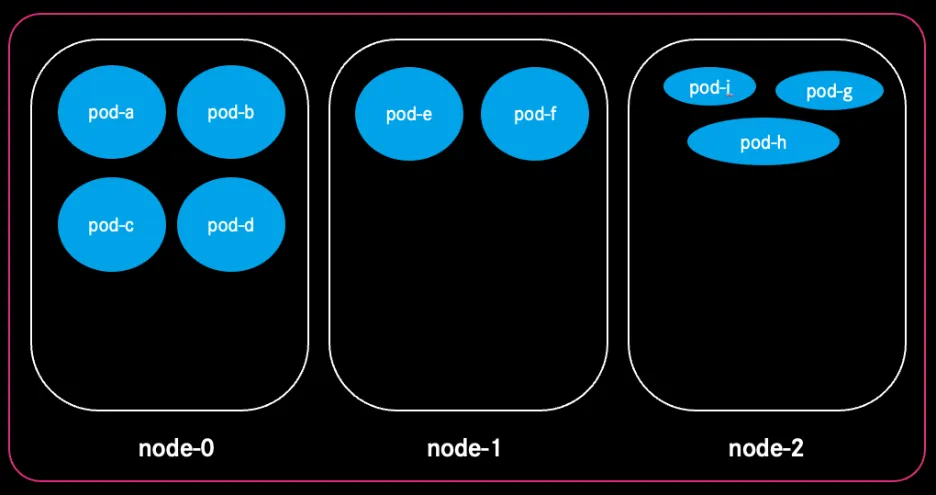
Smart Eviction for Runtime Bin‑Packing
One key feature mirrored from the Kubernetes Descheduler is runtime eviction. When Cast.ai detects that workloads could be placed more efficiently, for example, because a different node type could pack them better, it evicts pods safely, drains nodes gracefully, and reschedules them to minimize waste.
This real‑time bin‑packing means our clusters continuously optimise themselves without requiring human intervention.
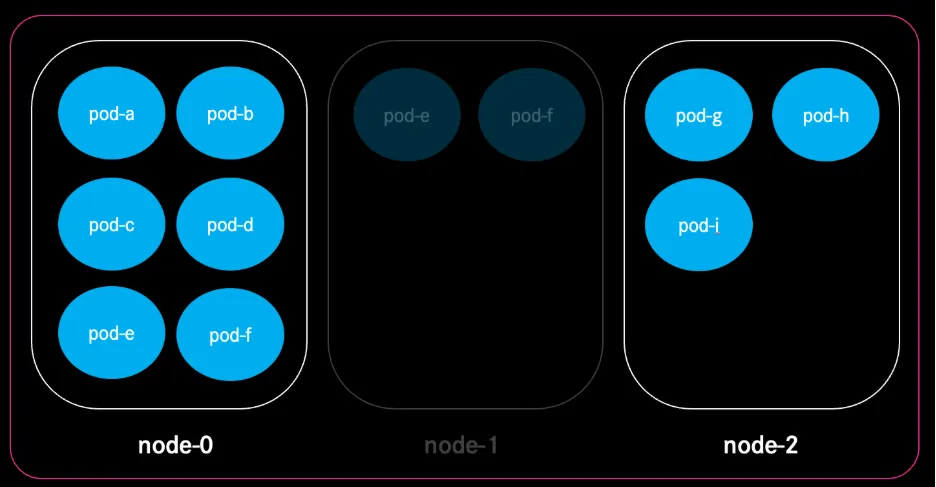
Smart Eviction during Rebalance Procedure
As fragmentation of workload still might occur, the Rebalance feature enables us to recalculate the current cluster state on demand. Based on the current resource requests, the optimal combination of instance types and families in relation to costs will be calculated, created and workload will be shifted.
Be Aware! Reliability in Eviction Procedures
Bear in mind that in cases of active eviction for your running workload reliability and high availability measures are key for seamless zero downtime operation. So tuning your workload with the following configurations is key:
- Running multiple replicas of your workload
- Liveness, Readiness and Startup probes
- Pod Disruption Budgets
- Real-world-sized resource requests and limits
- Pod Topology Spread Constraints
Workload Autoscaling
The principles discussed so far only tackle the optimised scaling and sizing of the underlying worker nodes within a Kubernetes cluster. But what if your workload itself requests too much or too few resources?
For the nodes to properly scale it’s crucial that the requested resources are set to real world conditions. Otherwise, your workload might starve or is over-provisioned. More serious consequences could be that your nodes run out of memory therefore killing processes randomly or CPUs are getting throttled and slowing down your application significantly.
To tackle this problem, automated and dynamic workload autoscaling can help you detect resource consumption of your workload in real-time and adapt resource request settings properly on the fly. The described solution is most commonly referred to as vertical pod autoscaling and can be integrated with tools like the Vertical Pod Autoscaler.
In opposition to vertical pod autoscaling you can also scale your workload horizontally, which basically means to increase or decrease the pod replica count dynamically in an automated way. Even though this way of scaling is important to run reliable applications and scaling based on demand I want to point out that even then proper resource request settings are crucial to prevent the risks mentioned above.
With the Cast.ai solution suite dynamic pod autoscaling comes as a feature without the additional installation and maintenance of other components.
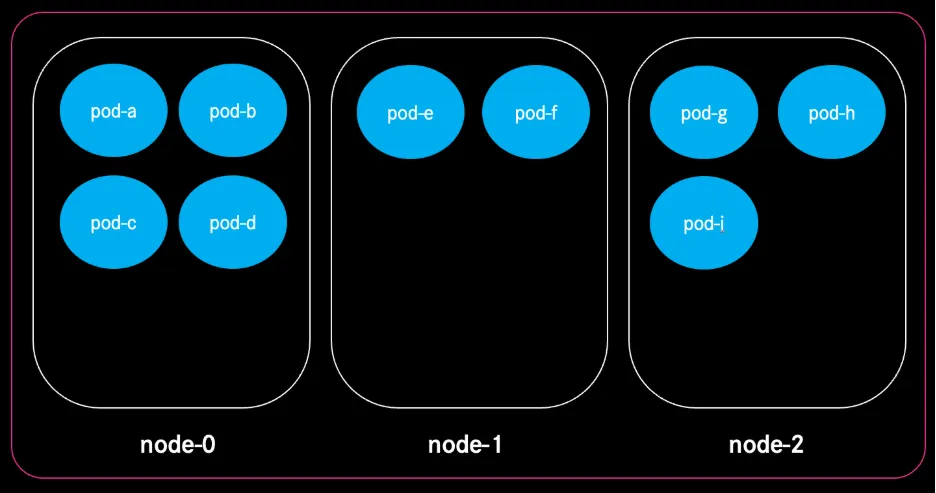
The Outcome
To summarize the above - a Kubernetes cluster setup with fragmented workload…
… may result in an optimised and efficiently used infrastructure, cutting your cloud costs significantly.
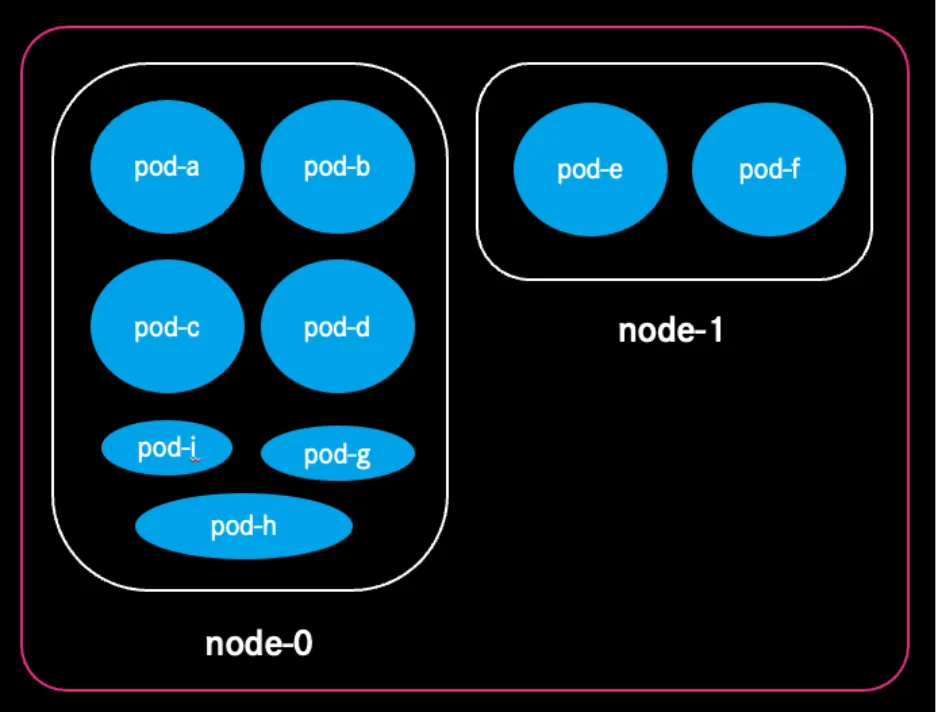
By adapting dynamic autoscaling principles powered by the Cast.ai solution suite, we achieved:
- Lower infrastructure costs through right-sized, on‑demand nodes
- Reduced fragmentation thanks to automated runtime bin-packing
- Simplified operations and less maintenance of instance types
- Zero downtime by applying state of the art reliability best practices
- Faster response to team needs without manual service requests
Most importantly, our platform team can now focus on building value, not babysitting VM instance types.
Transitioning to dynamic autoscaling has transformed our approach to cloud infrastructure management. By leveraging advanced automation and intelligent workload optimisation, we’ve not only cut costs and eliminated manual overhead, but also ensured our systems remain resilient and responsive to change. As we continue to scale and innovate, adopting a managed solution empowers our team to dedicate more time to strategic initiatives, confident in a future-proof, self-optimising platform that grows with our business.
Remaining Challenges
As the real world is unfortunately not perfect there are some challenges, we continue to face which impact the optimised usage of the cluster:
The workloads of our product teams rely heavily on Java and JVM usage. This conflicts by design with a lot of advantages Kubernetes brings to the table but in short, the caveats regarding autoscaling:
- JVMs do have a very high CPU usage during start up times in comparison to runtime. This makes it quite difficult to set proper resource request values as they might be too low for a proper start up but too high for the runtime. With Kubernetes 1.33 this challenge might be tackled with the In-Place Pod Resize feature, but nevertheless it will not be the silver bullet since product teams will need to be familiarised with the requirements and behavior of their workload, but in the end of the day it’s one more tool that Kubernetes will give us to explore the constant path of optimisation.
- Memory is (more or less) requested at the start-up of the JVM so by design there is no dynamic scaling possible.
Related articles

André Félix
From Cool Demos to Production Reality: Insights from the April Lisbon JUG Java Meetup
At Mercedes-Benz.io, we actively engage with local and international tech communities to explore how emerging technologies can be applied responsibly in enterprise environments. In April, we were proud to take part in th
May 19, 2026

Romina Muenchow-Centili
AI in Service Management: Driving Efficiency, Quality and Impact
Artificial Intelligence (AI) is no longer a distant promise in Service Management, it is already reshaping how teams work, think and deliver value. In this edition of Technkowledgy, Romina Muenchow-Centili, Service Manag
May 12, 2026

João Almeida
Behind the Engine: How Carl.AI Scales Knowledge Access at Mercedes-Benz.io
At Mercedes-Benz.io, not every product we build is visible to customers. Some of the most important ones work quietly behind the scenes, shaping how teams collaborate, share knowledge, and build digital products more eff
Apr 28, 2026